Understanding Attention Mechanisms in Transformer-Based AI Models
- pradnyanarkhede
- Mar 13, 2025
- 16 min read
Updated: Apr 29, 2025
A Comprehensive Work Done by -
Yashkumar Rathod-123B1B245
Ved Rathod-123B1B244
Sahilkumar Patel-123B1B254
Introduction
Over the last few decades, the development of artificial intelligence has gone through an enormous number of innovations, changing the attitude towards integrating technology into social life. However, one of the most innovative and important attention alternations of an approach incorporated into AI is considered a field of planning, where attention is paid in particular to the description of modifications based on real innovations and the practical implementation of transformer-based models. This step changed how AIs deal with data sequences, giving them enormous possibilities in many fields, including but not limited to understanding languages, identifying and categorizing images, scientific research, and much more. But what is an attention mechanism, and how did it become so vital in AI and technology progress?
The purpose of attention mechanisms is to establish an effective solution to a problem faced by sequential information, maintaining pertinent information IV over advanced sequential distances. Most traditional networks found this difficult, as even a single repetitive loop led to them forgetting important features while going through long data sequences. This challenge is best illustrated with the example of reading a complex novel. If one would try to read a novel with so many plot twists within word by word approach implemented through a very small window showing only one word with a handful surrounding words, capturing vital themes and ideas becoming part of the story in the earlier sections. The challenge posed was faced by the sequential models, such as RNNs and other models, till the emergence of attention algorithms.
Attention as a concept within deep learning stemmed from a paradigm shift. When working with streaming data, instead of using a funnel, what if direct access routes existed for every single object being processed? This would grant a model the capacity to 'pay attention' to any relevant information regardless of its position within the entire input sequence. Attention enables humans to link compelling concepts placed in distinct paragraphs and similarly enables AI models to make sense of positions in a sequence where a plethora of variables are separated by large distances.
These mechanisms have increased in utility and importance over time, constituting now the defining feature of modern AI systems. A wholly attention-based architecture, the transformer, is the backbone of a new breed of models, BERT, GPT, and T5, which have revolutionized natural language processing. These models perform exceptionally well for a wide array of tasks, such as machine translation, text summarization, question answering, and even creative writing.
We'll explore very carefully how attention mechanisms function in transformer-based models. We will investigate the types of attention, such as self and multihead attention, and analyze their practical applications in different fields. This will be useful for anyone who would like to understand the more commonly used techniques in AI, regardless of whether or not they are new to AI or are experts.
Before You Begin
This blog presupposes a minimal knowledge in understanding the fundamentals of machine learning. If you are new to these concepts, here are some useful definitions of the terms used throughout the text:
Artificial Neurons: Frameworks of synthetic neurons that acquire learned data patterns.
Words or other attributes: A dictionary-like calculation of objects.
Probability: The chance aspect of a particular situation event.
Two-dimensional mathematical objects: Primary activities such as multiplying two or more matrices.
You do not need to have a sophisticated Master’s degree in Machine Learning to follow the text. You can understand the fundamental concepts as we will cover them along the way.
The Evolution of Neural Networks: From Sequential Processing to Attention
To understand the importance of attention mechanisms, it is imperative to first explain the processes they are meant to evade. Step by step, the coexistence of classical neural networks and attention-based transformers is a defining moment in the treatment of sequence data in artificial intelligence.
The first hurdle for Early neural networks was the acceptance of a scope beyond image classification and numerical prediction. They faced a massive struggle with sequential data such as text, speech, or time series due to the variable size of input and somewhat important sequential arrangement of elements. The Recurrent Neural Networks (RNNs) were developed to tackle this complex problem using a new strategy called the memory: information could now persist through time.
RNNs operate linearly. They scan through the data, element-by-element. They keep an updated secret state with each new element. To a certain degree, this solved the problem of sequential data since the networks now had a sense of order. Unfortunately, RNNs encountered one major challenge: maintaining context over distance as the sequences became more extensive. Early information in a sequence would be able to do little to nothing due to the myriad of processing steps that joined failure to that information the “vanishing gradient problem.”
Researchers have tried to extend the capabilities of traditional neural networks with more complex architectures such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) with additional features to better retain information over time. While these improvements were beneficial, they were still fundamentally limited by the requirement of sequential processing, meaning that each piece of information needed to be processed in a linear order from one element to the other.
Though originally used for image recognition, Convolutional Neural Networks (CNNs) were also used with sequential data. They were good at identifying local features but could not capture long-range dependencies without putting several layers on top of one another. Because of the hierarchical structure of CNNs, they were able to progressively capture representations of higher-level contexts, but this was still insufficient for capturing relationships between far-apart constituents.
The introduction of attention mechanisms solved this problem. Instead of forcing information to be passed through a narrow channel sequentially, attention enabled the creation of shortcuts between two elements of a sequence regardless of how far apart they are. This was completely different from how things were done before, as it solved the problem of sequential models.
Consider having to read a dense and convoluted text. This is how traditional RNNs operate, which is reading a document through a narrow window and trying to remember important things as you go. With attention, however, you have a complete view of the document, which enables you to zoom in on accurate parts without losing sight of the context. This superpower of rendering irrelevant details inconsequential is how attention mechanisms derive their power and name, respectively.
The Transformer architecture came with a model built around attention in complete absence of recurrence or convolution. This was first introduced in the 2017 Paper by Vaswani et al, named ‘Attention is All you Need’. This architecture processed entire sequences in parallel instead of sequentially, which improved performance and training efficiency skyrocketed.
The move from sequential processes into attention-based ones is perhaps one of the greatest shifts throughout the history of Neural Networks. Being able to bridge the gap between the most distinct elements in a sequence fundamentally provided the scope of developing a new era of AI technologies. Attention mechanisms, after all, break centuries worth of boundaries.
Fundamentals of Attention: The Query-Key-Value Paradigm
The attention mechanism stems from an elegant model called Query-Key-Value (QKV) framework. This model is relevant to figure out how attention is computed and why it is so good at capturing relationships among elements in a sequence.
To illustrate a paradigm that is easy to grasp, let’s consider an example that most of us feel comfortable with: looking up information in a library. Imagine you are visiting a library with a particular question in mind; what you are doing is something akin to attending to something. Your question is the query, and ask you are looking, in this case, the library has books, but it does not contain some random text. Each book has catalog information that is referred to as keys and tells what the book contains, and the content that is inside the book is the value that you seek.
In this example, attention works exactly in the same way. You have a query, in this case, a question that you need to find an answer to. The task is to compare this question with the keys of all available books and find out which books are most likely to contain the answer to your question. Then, you selectively attend to the most relevant books and ignore the irrelevant ones. It is important to note that in this case, you do not have a single answer from a single book. You have answers from multiple books, and you give more weight to the relevant books when you combine the information from multiple sources.
Translating this analogy to the mathematical formulation of attention, we have three main components:
Queries (Q): Representations of what we're looking for or what we want to focus on
Keys (K): Representations that help determine relevance to the queries
Values (V): The actual content that gets weighted according to the relevance scores
In the context of a neural network, these components are typically created through linear transformations of the input representations. For each position in a sequence, we create a query vector and then compare it against key vectors from all positions (including itself) to determine relevance scores. These scores are then used to create a weighted sum of the value vectors, producing the output of the attention mechanism.
The mathematical formulation of this process is surprisingly elegant:
Attention(Q, K, V) = softmax(QK^T / √d_k)V
Let's break this down step by step:
QK^T represents the matrix multiplication of the query matrix Q with the transpose of the key matrix K, resulting in a matrix of compatibility scores between all queries and keys.
The division by √d_k (where d_k is the dimension of the key vectors) is a scaling factor that helps stabilize gradients during training, preventing the softmax function from entering regions with extremely small gradients.
The softmax function converts these compatibility scores into a probability distribution, ensuring that the weights sum to 1 for each query.
Finally, these attention weights are used to compute a weighted sum of the value vectors, producing the output of the attention mechanism.
This formulation has several important properties that make it powerful:
First, it creates direct connections between any positions in the sequence, allowing information to flow without sequential constraints. This addresses the fundamental limitation of RNNs and enables the modeling of long-range dependencies.
Second, the attention weights are dynamic and content-based, meaning they depend on the actual content of the sequence rather than being fixed parameters. This allows the model to adapt its focus based on the specific inputs it receives.
Third, the softmax operation ensures that the model focuses more on relevant positions and less on irrelevant ones, mimicking the selective nature of human attention.
The Query-Key-Value paradigm provides not only a mathematical framework but also an intuitive way to think about attention. It captures the essence of how we selectively focus on information—by comparing what we're looking for (queries) against what's available (keys) to determine where to focus our attention (values). This elegant formulation has proven remarkably effective across a wide range of applications, from natural language processing to computer vision and beyond.
Self-Attention: The Core Mechanism of Transformers
Self-attention serves as a core concept in the architecture of transformer models. It may also represent a major leap forward in implementation of attention mechanisms. Unlike earlier attention methods that functioned across multiple sequences, such as the focus on the source and target sentences in machine translation, self-attention permits different elements within the same sequence to focus on one another. This modification enables models to construct rich, contextual representations of each element using its relations with all the other elements in the sequence.
Self attention’s strength stems from its capability of capturing relationships across data. In the case of natural language, these could include grammatical relations, coreference (nouns and pronouns referring to the same entities), semantic likeness, or even far-fetched logical relations. Generally sequential models faced challenges in capturing these relations, even more so when connected parts are distanced from one another. Self-attention addresses this issue by providing direct pathways between any two locations in a sequence.
To see self-attention in action, let's look at a concrete example: the following sentence: "The trophy wouldn't fit in the suitcase because it was too large." A human reader can at once realize that "it" is referring to "trophy," not "suitcase, —but such reference resolution has classically been difficult for AI systems. With self-attention, the model can learn to build strong relationships between "it" and "trophy" and between "large" and "trophy," and use them to resolve the reference correctly.
Self-attention accomplishes this by allowing each position to see every position in the sequence, including itself. For each position, the model computes query, key, and value vectors as learned linear transformations of the input embeddings. The model computes compatibility scores between the query vector at each position and the key vectors at each position. The scores are softmax-normalized to produce attention weights, which are used to compute a weighted sum of the value vectors.
Mathematically, the input sequence is represented by X. Mathematically, the self-attention mechanism can be formulated as:
Q = XW^Q (query vector construction)
K = XW^K (vectors of key generation)
V = XW^V (value vector creation)
Attention(Q, K, V) = softmax(QK^T / √d_k)V
Where W^Q, W^K, and W^V are matrices of learned parameters.
The result is a novel representation for every position in terms of a blend of information from all other positions, normalized by relevance. This allows the model to learn complex relationships regardless of distance, going beyond the inherent limitation of sequential models.
One way to represent self-attention is as matrices of attention weights, where one cell is an attention weight from one position to another. Such representations are often found to learn interpretable patterns, e.g., attention among related words, syntactic structure, or coreference. In our sentence describing the suitcase and trophy, we can see high attention weights between "trophy" and "it," meaning that the model has learned to connect the pronoun to its referent.
Self-attention is not unlimited, though, particularly in terms of computational costs. Since all positions pay attention to all positions, the computation increases quadratically with sequence length (O(n²) for sequence length n). This will be infeasible for very long sequences, motivating work on faster versions that will simulate full attention but with lower computational costs.
Despite this constraint, self-attention has worked remarkably well for many tasks. By allowing direct modeling of any-to-any relations within a sequence, it has revolutionized sequence modeling and has enabled new directions in AI. Its capability to model long-range dependencies and intricate relations has made self-attention the central mechanism of transformer models and a pillar of contemporary AI systems.
Multi-Head Attention: Capturing Different Types of Relationships
Self-attention is an efficient way to model intra-sequence relations, but complex data requires attending to several different types of relations simultaneously, which cannot be achieved with one attention function. This shortcoming gave rise to multi-head attention, an advanced feature that enables transformer models to focus on data from separate representation subspaces located at different positions simultaneously.
To grasp the thinking behind multi-head attention, think about the human approach to multi-layered information. When we read, we do not concentrate on a single feature of the text but rather on an entire constellation of features, including grammar, semantics, narrative, and the factual elements of the text. In the same way, multi-head attention enables models of transformers to look at the same data from several different angles simultaneously to understand various relationships within the datasets.
With multi-head attention, the attention mechanism involves dividing the query, key, and value vectors into several heads, each with their own space they concentrate on. Each “head” calculates its attention independent of the other heads, after which the results are concatenated and linearly transformed to yield the final output. This makes it possible for the model to focus on representation subspaces at different positions simultaneously.
In mathematical terms, multi-head attention can be represented as follows:
MultiHead(Q, K, V) = Concat(head₁, head₂, ..., headₕ)W^O
Where:
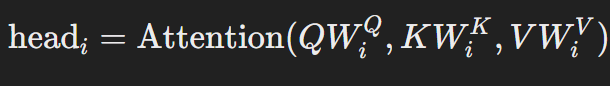
In this case, W^Q_i, W^K_i, W^V_i, W^O are the learned parameter matrices, and h is the number of heads.
The effectiveness of multi-head attention becomes evident once we look into what different heads learn. Different attention heads often tend to focus on different types of relationships, as research indicates.
1 . Syntactic Relationships: Some heads specialize in the grammatical structure of sentences, for example, relationships between subjects and verbs, articles and nouns, or any syntactic dependencies.
2 . Semantic Relationships: Other heads specialize in the meaning of the sentences, for example, words of the same meaning or related concepts, regardless of their positions in the text.
3. Coreference Relationships: Some heads are focused on relating certain entities and their references, such as pronouns and their antecedents.
4 . Positional Relationships: Some heads are focused on words that are located nearby, thereby capturing what is referred to as the locality of context or phrasal information.
This specialization takes shape by itself during training, without direct supervision, as different heads learn how to obtain different forms of useful information from the input.
The multi-head techniques have more advantages than the single head.
To start, it improves the model’s representational power by enabling it to focus on various types of relationships at the same time. This is crucial for complex data that possesses multiple layers of structure and meaning.
Next, it captures the interdependencies within the attention mechanism as a form of ensemble learning, where various heads complement each other and result in more accurate representations of the data.
Finally, it permits the model to simultaneously focus on various locations, which is particularly useful when several sections of the input are relevant to a single output location.
The number of attention heads is a hyperparameter that can be optimized according to the specific task and the available computational resources. The most frequent implementation of transformers uses from 8 to 16 heads to get the needed balance between representational capacity and computational resources.
Different multi-head attention implementations show different linguistic phenomenon using distinct heads. For example, one head in a machine translation model could be trained to align corresponding words in the two languages, while another captures the grammatical changes required to produce a fluent output.
Multi-head attention is an anadvancede feature that combines the simpler pieces of othe f attention mechanism, enabling transformer models to deal with a multitude of relationships simultaneously.
Attention Mechanisms in Practice: Real-World Applications
The power of attention mechanisms extends far beyond theoretical interest. These mechanisms have enabled remarkable advances across numerous domains:
Natural Language Processing
Machine Translation: Transformer models like Google's Neural Machine Translation system have
Dramatically improved translation quality by capturing contextual relationships between words across languages.
Text Summarization: Attention helps models identify the most salient information in documents, enabling more accurate and coherent summaries.
Question Answering: Systems can now understand complex questions and locate relevant information in large texts by attending to key relationships.
Computer Vision
Image Captioning: Attention allows models to focus on relevant parts of an image when generating descriptive captions.
Object Detection: Visual transformers can identify and locate multiple objects in images by attending to different visual features.
Medical Image Analysis: Attention mechanisms help highlight anomalies in medical scans, assisting in disease diagnosis.
Speech Recognition and Audio Processing
Speech-to-Text: Attention improves transcription accuracy by focusing on relevant audio segments.
Voice Assistants: Systems like Siri and Alexa use attention to better understand user queries in noisy environments.
Music Generation: Attention helps models capture temporal patterns in music for more coherent compositions.
The Future of Attention: Emerging Trends and Innovations
As attention mechanisms continue to evolve, several exciting trends are emerging:
Efficient Attention
Standard attention mechanisms have quadratic computational complexity, making them resource-intensive for long sequences. Researchers are developing more efficient variants like:
Sparse Attention: Only attending to a subset of positions
Linear Attention: Reformulating attention to achieve linear complexity
Longformer and Reformer: Models designed specifically for processing very long documents
Interpretable Attention
As AI systems take on more critical roles, understanding how they make decisions becomes increasingly important. Attention weights offer a window into model reasoning, showing which inputs influenced particular outputs. This interpretability is crucial for applications in healthcare, finance, and legal domains.
Cross-Modal Attention
The ability to attend across different types of data (text, images, audio) is opening new frontiers in AI. Models can now understand relationships between words in a caption and regions in an image or between spoken words and corresponding video frames.
Hierarchical Attention
Building attention mechanisms that work across different levels of abstraction—from characters to words to sentences to documents—promises a more nuanced understanding of complex content.
Conclusion: The Transformative Power of Paying Attention
Attention mechanisms have transformed the processing and understanding of information. In imitating the human ability to identify the most significant thing, such mechanisms have enabled models to represent complex relationships, handle long-range dependencies, and achieve unprecedented performance across diverse tasks.
As we proceed further and enhance attention mechanisms further, we're closer to AI systems that can capture the rich, contextual nature of human communication and the world we inhabit.T he evolution from rudimentary attention to the sophisticated multi-head attention of contemporary transformers is one of the largest breakthroughs in artificial intelligence—a testament to how sometimes the most powerful innovations are founded on teaching machines to focus on what actual problems.
Whether you're a programmer interested in deploying these models or a business executive interested in pursuing AI applications or are simply interested in the technology behind the current AI boom, understanding attention mechanisms enlightens us about how modern AI thinks, learns, and generates.
The limelight of focus has shed light on new avenues in artificial intelligence, and as we move forward in an attempt to evolve and perfect these mechanisms, the light will intensify further, creating new avenues in what computers can comprehend and accomplish.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. International Conference on Learning Representations.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT 2019.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations.
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., ... & Hassabis, D. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873), 583-589.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. International Conference on Machine Learning.
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., ... & Belanger, D. (2021). Rethinking Attention with Performers. International Conference on Learning Representations.
Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., ... & Ahmed, A. (2020). Big Bird: Transformers for Longer Sequences. Advances in Neural Information Processing Systems, 33.
Tay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2020). Efficient Transformers: A Survey. ACM Computing Surveys.
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., & Carreira, J. (2021). Perceiver: General Perception with Iterative Attention. International Conference on Machine Learning.
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., ... & Sutskever, I. (2021). Zero-Shot Text-to-Image Generation. International Conference on Machine Learning.
Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., ... & Irving, G. (2021). Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv preprint arXiv: 2112.11446.
Clark, K., Khandelwal, U., Levy, O., & Manning, C. D. (2019). What Does BERT Look At? An Analysis of BERT's Attention. BlackboxNLP Workshop at ACL.
Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The Long-Document Transformer. arXiv preprintarXiv: 2004.051500.
Glossary
Attention Mechanism: A technique that allows a model to focus on specific parts of the input when producing an output.
Attention Weights: Values that determine how much focus is placed on different parts of the input.
BERT (Bidirectional Encoder Representations from Transformers): A transformer-based model that processes text bidirectionally.
Embedding: A numerical representation of a word or token that captures its meaning.
Encoder: The part of a transformer that processes the input sequence.
Decoder: The part of a transformer that generates the output sequence.
Feed-Forward Network: A fully connected neural network layer used in transformers after attention mechanisms.
GPT (Generative Pre-trained Transformer): A transformer-based model designed for text generation.
Layer Normalization: A technique used in transformers to stabilize the learning process.
Multi-Head Attention: A technique that runs multiple attention operations in parallel to capture different types of relationships.
Positional Encoding: Information is added to embeddings to indicate the position of each token in a sequence.
Query, Key, Value (Q, K, V): Three different transformations of the input used in attention calculations.
Residual Connection: A connection that adds the input of a layer to its output, helping with gradient flow during training.
Self-Attention: A type of attention where each element in a sequence attends to all elements in the same sequence.
Softmax: A function that converts a vector of numbers into a probability distribution.
Transformer: A neural network architecture that relies primarily on attention mechanisms instead of recurrence.
Vision Transformer (ViT): A transformer architecture adapted for image processing tasks.



Good research
Nice work.
Nice
Wow!! Nice Work
Nice content!!