The Role of Self-Attention in Generative AI Models
- pradnyanarkhede
- Mar 11, 2025
- 3 min read
Updated: Mar 12, 2025
By: Shivprasad A. Mahind
Rushikesh Patil
Shreeya Patil
1. Introduction
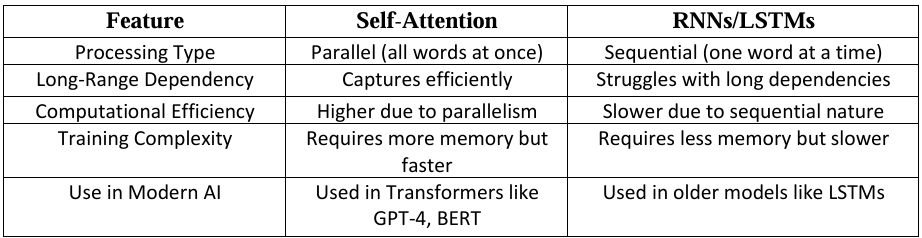
Self-attention is a technique that helps AI understand and generate complex content like text, images, and speech more effectively. Unlike older models like RNNs & LSTMs, that process information step by step, self-attention looks at everything at once, making it faster and better at understanding relationships between different parts of the input.
Why Self-Attention Matters?
• It processes information all at once instead of one piece at a time.
• It connects ideas that are far apart, improving understanding.
• It powers advanced AI tools like ChatGPT and image generators like ChatGPT, DALL·E.


Comparison of RNN vs. Self-Attention
2. Understanding Self-Attention
How Does Self-Attention Work?
Imagine reading a sentence where a word at the beginning is connected to one at the end. Self-attention helps AI notice and understand these connections. It does this in a few steps:
Computing Query (Q), Key (K), and Value (V) matrices for input words.
Calculating attention scores using the dot product of Q and K.
Applying the softmax function to normalize attention scores into probabilities.
Computing a weighted sum of the Value (V) matrix to get the final output.
Mathematical Representation of Self-Attention
The attention mechanism can be expressed mathematically as:
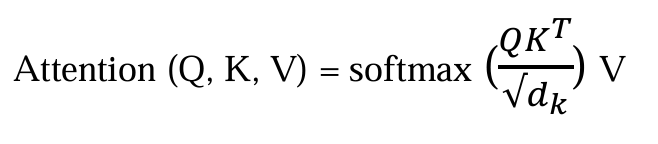
Where:
Q = Query matrix (Represents the current word’s representation)
K = Key matrix (Represents all other words in the sequence)
V = Value matrix (Holds contextual word representations)
d_k = Dimensionality of key vectors (Scaling factor to stabilize gradients)
The softmax function ensures that attention weights sum to 1, preventing instability in training.
3. Multi-Head Self-Attention
Instead of just one set of comparisons, AI uses multiple attention layers, each focusing on different aspects of the input. This helps it understand not only what the words mean but also how they are used in context.
Why Multi-Head Attention?
• Helps understand multiple word relationships (e.g., syntax, semantics).
• Enhances the model’s ability to differentiate word meanings.
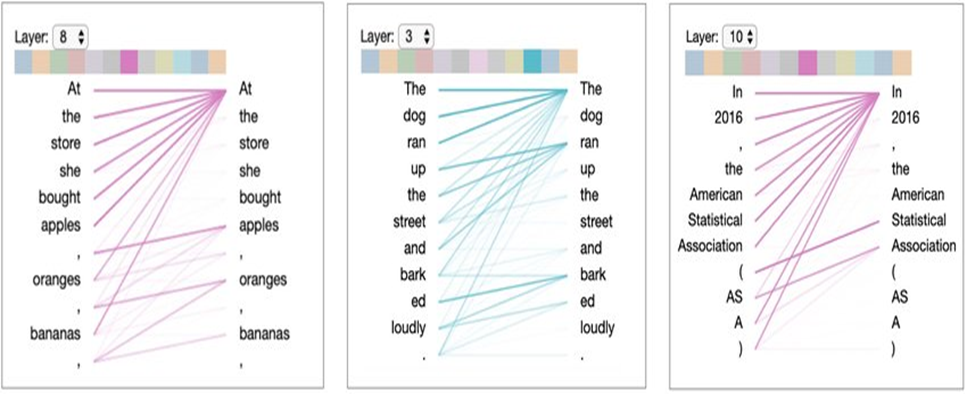
Diagram: Multi-Head Self-Attention
4. Self-Attention in Transformer Architecture
Modern AI models like ChatGPT and image generators rely on self-attention to:
• Process information quickly: They analyze entire sentences at once instead of word by word.
• Understand better: They can connect words even if they are far apart.
• Improve accuracy: They generate more relevant and meaningful responses.
Diagram: Transformer Model Overview
Block diagram of a Transformer, highlighting the role of self-attention layers.
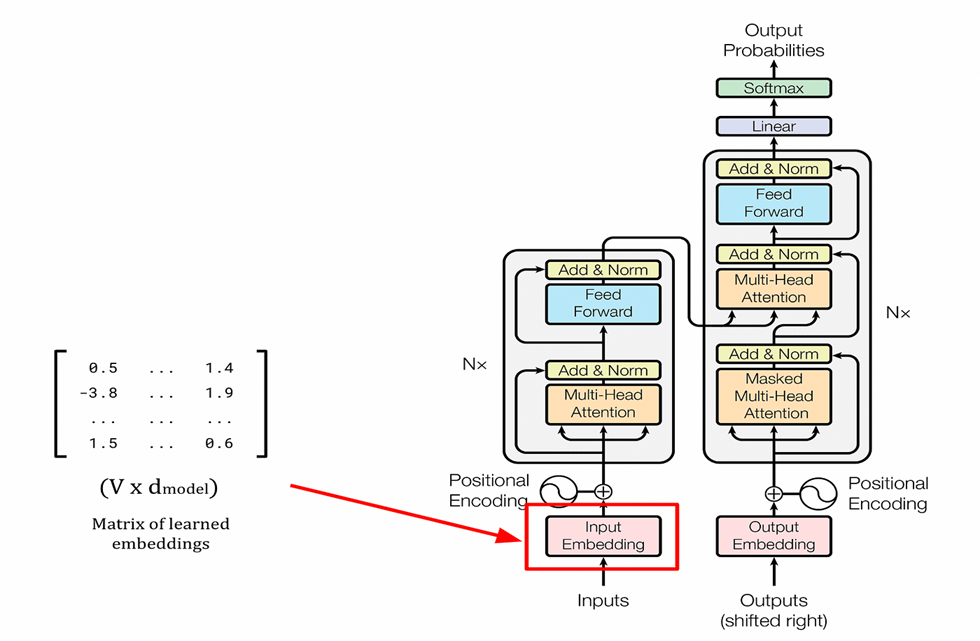
5. Advantages of Self-Attention in Generative AI
• Parallelization: Unlike RNNs, self-attention can process all words at once.
• Captures long-range dependencies: It can relate words far apart in a sentence.
• Efficiency: Works well for large datasets and high-dimensional data.
6. Applications in Generative AI
Real-World Uses of Self-Attention
1. Text Generation – ChatGPT, Claude, Gemini
2. Image Generation – DALL·E, MidJourney
3. Speech Recognition & Translation – Google Translate, DeepL
4. Music Generation – OpenAI’s Jukebox, MusicLM
5. Protein Folding & Drug Discovery – AlphaFold
7. Conclusion
Self-attention has made AI much smarter and more efficient. It allows AI to understand and generate content in a way that feels more natural and useful. In the future, we can expect improvements that make AI even faster and more affordable to use.
What’s Next?
Making AI models run with less computing power.
Improving AI’s ability to explain its decisions.
Combining self-attention with other techniques for even better results.
With self-attention, AI is becoming more powerful, opening the door to even more incredible innovations!


Your progress is truly inspiring.
Informative 👍👍
Extremely insightful and helpful!!
Great breakdown of the topic, very well structured!
GREAT !!!