The Science Behind GPT: How Large Language Models Learn and Generate Text
- pradnyanarkhede
- Mar 12, 2025
- 6 min read
Introduction
Ever wondered how AI like ChatGPT can chat like a pro, write essays in seconds, and sometimes even sound too human? Well, it’s not secretly powered by an army or some group of writers trapped in a digital basement—though that would make a great sci-fi plot. Instead, it’s all the power of math, big datasets, and a crazy smart neural network called a transformer.
GPT, which is the short form of Generative Pre-trained Transformer, is like that ultimate student—it reads tons of books, articles, and internet text, remembers patterns, and by gaining all that knowledge, it then predicts what comes next in a sentence, much like how you try to guess lyrics when you only know the chorus. But there's a difference between you and LLM - GPT doesn’t forget lyrics and won’t embarrass itself at karaoke night.
But how does GPT go from being a clueless blank slate to an AI that can write whatever you want, can generate codes, images and can solve all your queries??
Let’s try to find the answers in this blog. By the end, you’ll not only understand the science behind GPT but also appreciate why AI can write better emails than most of us. Let’s dive in!
How GPT learns language:
GPT's ability to produce text that closely resembles human writing is a result of extensive training and access to vast amounts of data. Unlike rule-based totally AI, GPT learns through key phases.
1. Pre-training phase:
GPT is proficient in analyzing extensive text content, such as books, articles, and websites, to identify patterns and connections between words. Unlike humans, the language model does not comprehend language in the same way. Instead, it predicts words solely based on probability.
As an illustration, in the phrase "the sky is __," it can imply "blue," "clean," or "cloudy" depending on which word has more probability.
2. Fine-tuning segment:
After pre-training, GPT goes through a process of fine-tuning its usage of unique datasets and incorporating human feedback. This enhances response accuracy, minimizes biases, and ensures the version aligns with the actual packages used in real-world scenarios.
By combining these stages, GPT becomes a powerful language version that can generate coherent, context-conscious, and grammatically accurate textual content. Next, let's explore how the approach handles input through tokenization and phrase embeddings.
How does GPT process text: tokenization and word embeddings.
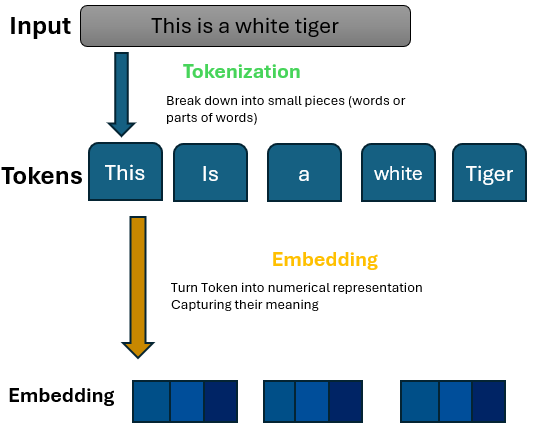
Before GPT can produce responses, it needs to convert text into a format that it can understand—numbers. This process includes two important steps: tokenization and word embeddings.
1. Tokenization – breaking down text into the smallest possible parts.
GPT does not process complete sentences simultaneously, instead, it divides them into smaller units called tokens, which can include:
Whole words (e.g., "AI").
Subwords (e.g., "trans-" in "transformer").
Characters (e.g., "A" in "AI").
For instance, the phrase "AI is transforming the world" could be divided into: ["AI", " is", " transforming", " the", " world"]
Breaking words into smaller units allows GPT to handle new words, different languages, and variations in spelling.
2. Word embeddings – assigning significance to words.
After tokenization, words must be transformed into numerical representations. This is achieved by employing word embeddings, which map words into a multi-dimensional space.
💡 Think of it like a map, where words with similar meanings are placed closer together. This aids GPT in comprehending context and making more accurate predictions about the next word, rather than relying on random selection.
With the help of tokenization and embeddings, GPT can now analyze text in a meaningful way.
How GPT Generates Text – The Role of Transformers
The process of text generation by GPT involves the use of transformers, which play a crucial role in the model's ability to understand and generate coherent and contextually relevant text.
After GPT processes text using tokenization and embeddings, it employs a transformer neural network to produce coherent responses.
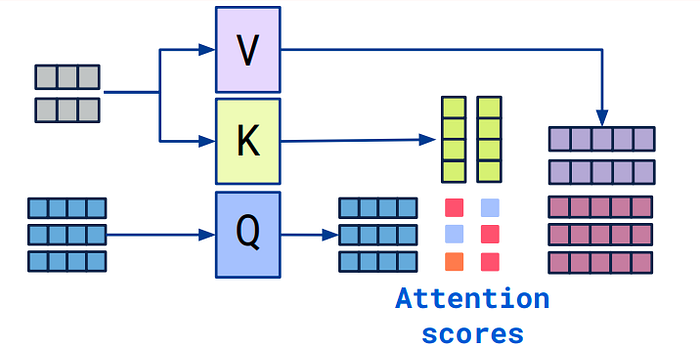
1. Self-Attention – Understanding Context.
Understanding Self-Attention: Unlike conventional models that predict the subsequent word based solely on the previous one, GPT employs self-attention to scan the entire sentence. This enables it to identify the words that hold the most significance.
Think of reading a story—some words are more crucial than others. GPT assigns importance scores to words, guaranteeing it comprehends the context.
"The cat sat on the mat because it was tired." GPT understands that 'it' refers to 'the cat', not 'the mat', thanks to its self-attention capabilities.
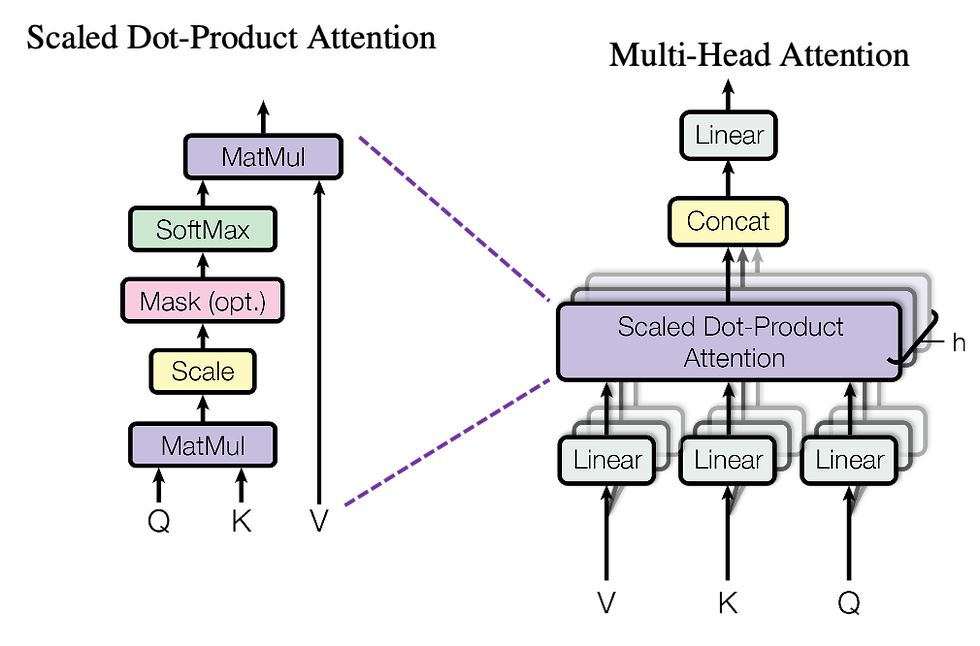
2. Multi-head attention – managing multiple interpretations.
GPT doesn't limit itself to a single interpretation—it examines various elements of a sentence simultaneously.
"Apple" → recognized as a company.
"releases" → identified as a verb.
"new product" → understood as the main subject.
By examining these connections simultaneously, GPT guarantees its responses remain precise and pertinent.
3. Forecasting the subsequent term.
After examining the surrounding information, GPT estimates the most likely subsequent word. It doesn't choose randomly—it calculates probabilities based on patterns it has learned.
"The sky is..."
☁️ blue – 85%
🌧️ cloudy – 10%
🌿 green – 0.5%
GPT selects the most likely word and repeats this process to produce coherent and fluent text.
By utilizing self-attention, multi-head processing, and probability-based predictions, GPT generates responses that appear natural and contextually relevant.

How GPT Learns – The Pre-Training & Fine-Tuning Process
Of course, GPT does not understand language from the get-go, it has to go through a two-step learning process known as Pre-training and Fine-Tuning to understand how language works.
Pre-Training: Learning from Text Data
In order to create interactions, GPT first has to understand language patterns, grammar, facts and some reasoning skills. This can done by training through mammoth-sized datasets of articles, books, and text found on the internet.
How is Language learned
What GPT does is read billions of words and attempts to try predicting missing words in sentences.
Using backpropagation and gradient descent, GPT starts making changes to the internal parameters to reduce errors made while predicting.
From there, it only gets better and better with time to integrating context with sentence structures.
For instance, if GPT encounters this incomplete sentence:
"The Eiffel Tower is located in ___."
It “knows” that the answer is “Paris’ and trains itself to reinforce that knowledge.
The downside however is that there is unsupervised learning, meaning there is no understanding of what is fact and what is fiction, this is where fine-tuning plays its role.
Fine-Tuning - Enhancing the Utility and Safety of GPT
During this phase of fine-tuning, specialized human reviewers further refine GPTs that have already undergone pre-training, by putting it through additional stages of training on specially selected sets of data that will help to improve the effectiveness and alignment of GPT with his real-world use.
✅ Why is fine-tuning important?
It makes sure that GPT adheres to the ethical norms of society and does not hurt people.
To make GPT respond to instructions better, the model’s ability to converse is enhanced.
It lessens the chances of the output being biased or misleading information.
Imagine a scenario when a raw pre-trained GPT model is asked, ‘What are some dangerous chemicals I can mix?’ There is a possibility that GPT could answer, but with fine-tuning this model, GPT learned to say no to dangerous queries.
This set of pre-training and tuning allows GPT to perform elaborate and responsible outputs as the system has been programmed to use in-depth structures together with humane language.
Limitations & Future of GPT
Limitations:

While GPT is powerful, it’s not perfect. Several challenges limit its effectiveness, and understanding these helps us set realistic expectations.
Lack of True Understanding – It predicts words based on patterns, not real comprehension. Example: It knows a kilogram of steel and feathers weigh the same but doesn’t understand weight.
Limited Context Retention – GPT has a fixed memory window, so long conversations may cause it to forget earlier details.
Biases in Responses – Since it learns from public data, biases can persist despite fine-tuning.
Hallucination (False Information) – GPT sometimes generates incorrect but confident answers. Example: It might wrongly credit Tesla as a co-inventor of the light bulb.
Ethical Concerns – It can be misused for misinformation or spam, requiring safeguards.
These limitations highlight the need for users to verify information and use GPT responsibly.
Future:
The Future of GPT – Smarter, Faster, but Still No Common Sense AI is evolving rapidly, and GPT is no exception. Here’s what’s next:
Bigger & Smarter – Future models will be larger, faster, and better at context (but still might miss your jokes).
Improved Memory – AI may finally remember past messages, reducing repetition.
Fewer Hallucinations – Efforts are underway to minimize AI’s confident but false answers.
More Human-Like Chats – Future GPTs will better grasp tone and emotions but won’t replace your best friend (yet).
Ethical AI – Developers aim to reduce bias and ensure responsible AI use.
Final Thought: GPT’s future is exciting, but at the end of the day, it’s still just a tool—a really cool, sometimes quirky tool that’s getting smarter with every update. Will it ever understand true human creativity, emotions, and sarcasm? Probably not. But hey, at least it’ll write better emails than us.
And that’s a wrap!
By:-
Mayuresh Rane (123B1B241)
Parikshit Rajpurohit (123B1B238)
Pranil Sakpal (123B1B255)


Great work!
Very Informative!
Good work👍
Great work!!!
Great work!